HLS设计流程
FPGA相当于可编程的ASIC,可以分为传统FPGA(7-Series、UltraScale以及UltraScale+)和SOC(Zynq-7000+和UltralScale+MPSoC)。
FPGA Architecture包括Programmable Logic、Programable I/O和Routing。
算法加速一般关注:Logic Unit(逻辑单元)、Arithmetic-logic Unit(算法逻辑单元)和Memory Unit(存储单元)。
Logic Unit: LUT、MUX、carry chain,主要是逻辑操作和加法操作
Arithmetic-logic Unit: DSP48,可以实现乘法、乘加、乘累加、累加以及逻辑运算。
Memory Unit: Block RAM和LUT(<1kb)。
RAM可以配置成下面几种模式:
Single port RAM
Simple-dual port RAM
True-dual port RAM
Single port ROM
Dual port ROM
FIFO
对于软件工程师来说,不需要关注各个单元每部的结构和实现,只需要关注每个单元的功能和特性,以及生成的HDL代码使用资源数量和性能。
HLS可以让程序员只需要关注用高级语言比如C语言对算法的描述,而不需要关注硬件语言对算法的实现,这个工作交由HLS来完成,这样极大地提升了程序员的开发效率。高级综合的过程分为Control Logic Extraction(生成一个限状态机)和Binding(每一个操作需要用什么资源)。
查看波形: 必须要有TestBench,然后是通过C/RTL CoSimulation来生成仿真波形图,配置如下:
void TopFun() {
SubFun1();
SubFun2();
}
C高级综合的代码风格
任意精度数据类型Arbitrary Precision Data Types
Language
Inter Data Type
Required Header
C
[u]int(1024 bits)
#include
C++
ap_[u]int(1024 bits) can be extended to 32K bits wide
#include
C++
ap_[u]fixed
#include
sizeof()函数可以返回上面的数据类型的字节数,取大小最近接的8的倍数。
任意精度的变量声明:
#define W 6
// copy initialization
ap_int a_6bit_var_c = 22;
// direct initialization
ap_int a_6bit_var_d(22);
// 任意进制的变量声明,前面的0b,0o,0x可以省略
ap_int a_6bit_var_r2("0b101010", 2);
ap_int a_6bit_var_r8("0o34", 8);
ap_int a_6bit_var_r16("0x2A", 16);
ap_[u]fixed中,W数据位宽;I表示整数部分位数;Q表示Quantization Mode(默认是AP_TRN_ZERO, Trumcation to zero);O表示Overflow Mode(默认是AP_WRAP, Wrap around)。
数据类型转换
Numeric Promotion,少位数的向多位数的转换,一般都是没有精度损失
Numeric Conversion,多位数向少位数的转换,可能会精度损失或者出错
对于二进制算术运算Binary Arithmetic Operator:
Operation
op1(M)
op2(N)
res
res = op1 + op2
ap_int
ap_int
ap_int
+
ap_uint
ap_uint
ap_uint
+
ap_uint
ap_int
M>N, ap_int; M<=N ap_int
res = op1 * op2
ap_int
ap_int
ap_int
*
ap_uint
ap_uint
ap_uint
res = op1 / op2
ap_int
ap_int
ap_int
/
ap_uint
ap_uint
ap_uint
res = op1 % op2
ap_int
ap_int
ap_int
%
ap_uint
ap_uint
ap_uint
使用typeid()这个函数能获取变量的类型,需要#include ,数值在参与计算的时候应该显式地将变量声明成对应的精度。
复合数据类型
结构体作为top function的时候,默认情况下,结构中scalar映射成scalar port;array被映射成memory port。建议将结构体定义在头文件中。结构体在HLS中优化称为data packing,Byte_Pack分为 field level和struct level;field level是让struct中所有元素位宽都是以8bit为边界;struct level是让结构体的位宽以8bit为边界而不用管每个元素的位宽。Data pack可以降低latency和initial interval。
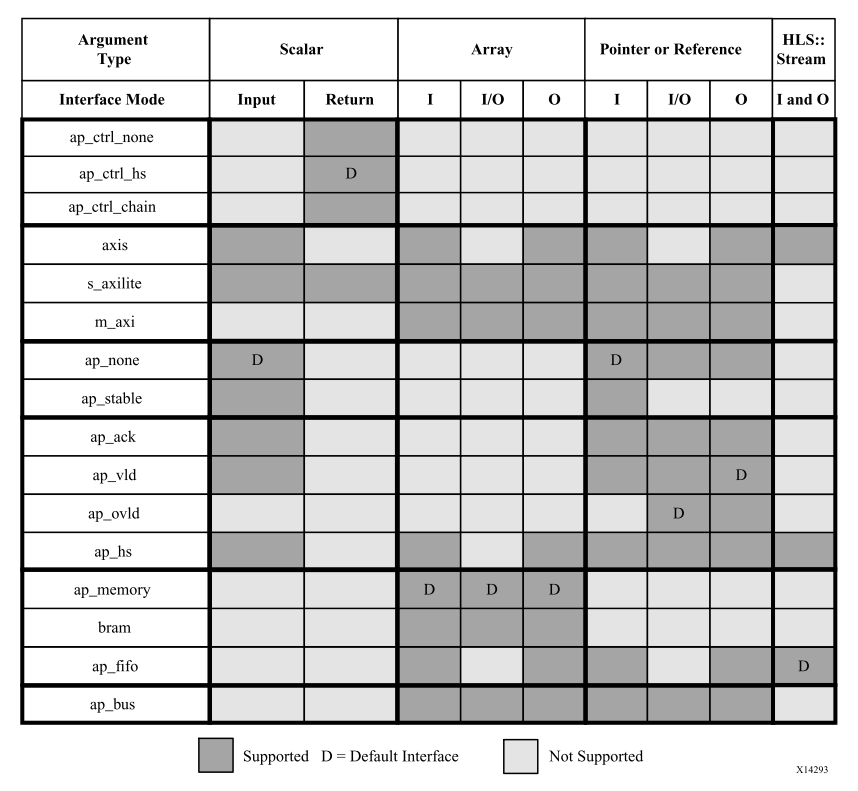
接口综合Interface Synthesis Overview
接口分为Block-level interface protocol和Port-level interface protocol。
Block-level interface protocol
只是作用于函数和函数的返回值,主要包括三种:
ap_ctrl_hs,握手协议,主要包括:ap_start, ap_ready, ap_idle, ap_done
ap_ctrl_none,没有上面的那些握手信号
ap_ctrl_chain,和ap_ctrl_hs相似,还多一个输入端口ap_continue
ap_start为高,表明这个模块处于工作;
ap_ready为高,表明这个模块能处理数据;
ap_done为高,表明这个模块执行完操作
Port-level interface protocol
No I/O Protocol
ap_none,表示没有I/O protocol作用于该port,scalar inputs默认为ap_none
ap_stable,表示input只会在设备复位时输入数据才会改变
Wire Handshakes
ap_ovld,用做in-out arguments;当in-out被拆分成input port和output port时,input port使用ap_none;output port使用ap_vld(输出有效信号);指针变量参数默认使用in-out。
ap_hs,包括ap_vld(表明当前输入或者输出是一个有效的)和ap_ack(给出一个应答)。
Array Arguments on the Top-level Function
默认将array arguments综合成RAM,可以配置使用single port或者dual port两种情况,并且HLS会自动的选择端口数量来是数据率最大。
对于数组作为参数可以通过directives来实现以下配置:
Using a single-port or dual-port RAM
Using FIFO interfaces
Partitioning into discrete port
对于下面的这段代码综合
void tutorial2(datatype a[M][N], datatype b[M][N]) {
int i, j;
for (i = 0; i < M; i++) {
for (j = 0; j < N; j++) {
b[i][j] = a[i][j] + 5;
}
}
}
a_address0: out, read address
a_ce0: out, chip enable
a_q0: in, input data to the block(output data from memory)
b_address0: out, write address
b_ce0: out, chip enable
b_we0: out, write enable
b_d0: out, output data from the block(input data to memory)
数组还可以优化成ap_fifo。
Adding Registers to IO ports
添加全局时钟使能信号,添加全局时钟使能型号以后,只有在全局时钟使能的情况下,整个硬件电路才会工作。
For循环的优化
基本衡量指标
Loop Iteration Latency:一个循环过程的时钟周期
Loop Iteration Interval:两次循环的之间的间隔
Loop Latency:执行所有循环的时钟周期(Trip Count × Loop Iteration Latency)
Function Latency:函数执行的时钟周期
Function Initial Interval:两次函数执行的间隔(不知道为什么和Function Latency不一致呢)
无嵌套For循环的优化
PIPELINE :一个很常用的用来减少循环latency的方法。
UNROLLING :循环默认是折叠的,可以将迭代的逻辑复制来展开循让迭代过程并行执行(相当于用空间来换时间吧);可以完全展开也可以部分展开,通过设置factor参数(迭代复制数量)。
LOOP_MERGE :引入loop_region(使用花括号括起来的部分定义为region),循环合并可以在一定程度上降低函数的latency和资源用量,因为没有合并之前可能会给不同循环创建额外的有限状态机。分为两个循环边界为常数(可以合并,合并后的边界取较大值),循环边界中有变量(不能直接合并,需要修改源码)。
循环边界为两个常数:
void tutorial1(dt a[M], dt b[M]) {
int i;
a_loop:
for (i = 0; i < M; i++) {
a[i] = i * i;
}
b_loop:
for (i = 0; i < N; i++) {
b[i] = i * i;
}
}
DATAFLOW :
下面这段代码,各个循环之间有数据依赖,每个循环之间的数据传输可以称之为channel,这些channel可以用ping-pong ram, fifo或者register
void tutorial1(dt a[M], dt b[M], dt c[M]) {
int i;
dt x[M];
dt y[M];
a_loop:
for (i = 0; i < M; i++) {
x[i] = a[i] + i;
}
b_loop:
for (i = 0; i < M; i++) {
y[i] = x[i] * b[i];
}
c_loop:
for (i = 0; i < M; i++) {
c[i] = y[i] -i;
}
}
嵌套的for循环
嵌套for循环分为:Perfect loop nest(内外层循环边界都是常数),Semi-Perfect loop nest(内存循环边界是常数,外层循环边界是变量)和imperfect loop nest(内外层循环边界是常量但是外层循环中有循环体或者外层循环边界是常量内层循环边界是变量),一般通过修改代码将imperfect loop nest转化成Perfect loop nest或者Semi-Perfect loop nest。
对外部for循环做pipeline,内部的for循环都会unroll。所以一般pipeline最内存的for循环可以在较少的资源利用上能获得不错的加速;而pipeline外层循环能获得更大的加速效果同时也占用更多的资源。
LOOP_FLATTEN :将内部的for循环展开并打平,要求两个嵌套的for循环是Perfect loop nest或者Semi-Perfect loop nest。
loop parallelism :
void tutorial1(dt a[M], dt b[M], dt x[M], dt y[M]) {
int i;
dt acc = 0;
dt bcc = 0;
a_loop:
for (i = 0; i < M; i++) {
acc += a[i];
x[i] = acc;
}
b_loop:
for (i = 0; i < M; i++) {
bcc += b[i];
y[i] = bcc;
}
}
PIPELINE with rewind option :一般的pipeline在执行完一个for循环到下一次for循环时中间会有一段间隔,使用rewind选项时候,会连续执行;但是有多个循环的时候不能使用rewind选项。
Automatic loop pipeline :在solution setting里面通过配置config_compile选项,设置automatic loop pipeline,pipeline_loops表示低于这个值得时候回自动pipeline,默认是0表示不会被pipeline。也可以使用pipeline directive中的disable loop pipelining选项来设置禁用automatic loop pipeline。
循环边界是变量的循环优化
循环变量是变量的情况在综合报告里面显示Latency和Interval是一个?;一般这种情况最好是缩小一个显示范围;主要有三种方法:
Tripcount directive
定义循环边界变量为ap_int类型,低位数的变量能自动控制变量的取值范围
使用assert语句
数组优化
resource directive来指定数组是以什么方式来实现。一般数组会以single-port RAM来实现;dual-port RAM一般用来减少initiation interval和latency;函数内部的数组一般映射成bram,lutram,ultraRAM或者register。
ARRAY_PARTITION
Single-dimension array
三种形式:(假设数组大小为6)
Block/Factor = 3,依次等分数组,表示0,1一组;2,3一组;4,5一组。
Cyclic/Factor = 3,隔个分一组,表示0,3一组;1,4一组;2,5一组。
Complete,完全并行分组,0,1,2,3,4,5分别表示六个组(存在6个register中)。
Multi-dimension array
对于多为数组来说,array partition中dim参数表示对应维度的partition,以a[3][6][4]为例:
dim = 1,分成a_0[6][4], a_1[6][4], a_2[6][4]
dim = 2,分成a_0[3][4], a_1[3][4], a_2[3][4], a_3[3][4], a_4[3][4], a_5[3][4]
dim = 3,分成a_0[3][6], a_1[3][6], a_2[3][6], a_3[3][6]
ARRAY_MAP
Array map就是将比较小的数组合并成一个大一点的数组,有两种方式来合并:
Horizontal Mapping:(get a single array with more elements),简单来说就是把一个数组追加到另外一个数组上;可以添加Offset选项,用这个选项添加两个数组之间的地址空档。这中方式会减少一些存储资源但是不会提升throughput。
Vertical Mapping:(get a single array with larger bit-width),将相应的位置的元素做位拼接,map以后的数组长度等于初始数组中较长的那个。
ARRAY_RESHAPE
Array reshape就是结合array partition和array vertical map,既可以减少bRAM的使用又可以parallel access to the data;array reshape是针对单个数组的优化。按照array partition的方式也对应分为三种方式:
函数的优化
INCLINE
Incline使用incline directive,incline可以减少函数调用部分的逻辑资源占用和时间;HLS中对逻辑简单的较小的函数自动的incline。
ALLOCATION
Allocation使用allocation directive,定义函数使用什么资源来实现,怎么实现;注意时间和空间的trade off。
DATAFLOW
Dataflow让函数或者循环顺序执行变成并行执行,增加数据吞吐率(throughput)
 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)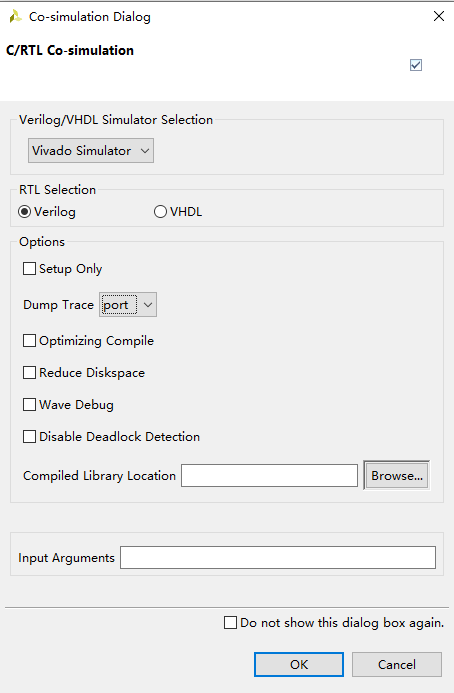 Simulator选择Vivado Simulator或者Auto;Dump Trace选择port或者all,确定仿真完成以后点波形查看器就可以查看波形。
对于下面这样拥有子函数的顶层函数,HLS会响应生成对应vhdl架构;如果子函数的逻辑很简单,HLS会自动INLINE下面的子函数,可以使用INLINE derective来开关这种内联。
Simulator选择Vivado Simulator或者Auto;Dump Trace选择port或者all,确定仿真完成以后点波形查看器就可以查看波形。
对于下面这样拥有子函数的顶层函数,HLS会响应生成对应vhdl架构;如果子函数的逻辑很简单,HLS会自动INLINE下面的子函数,可以使用INLINE derective来开关这种内联。
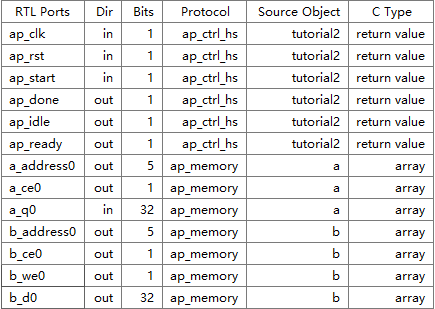 上面top function中的数组作为参数输入,默认被综合成了ap_memory。
上面top function中的数组作为参数输入,默认被综合成了ap_memory。
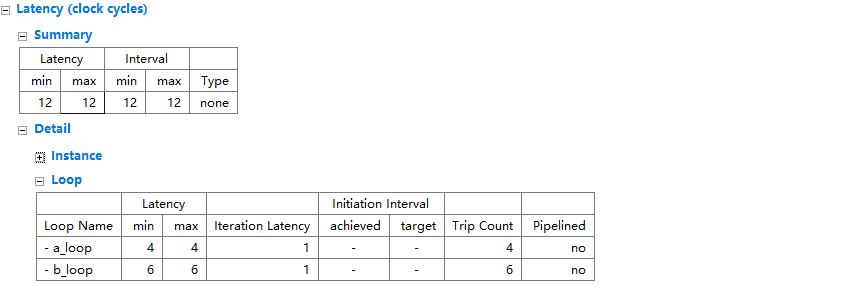 loop_merge以后的综合报告:
loop_merge以后的综合报告:
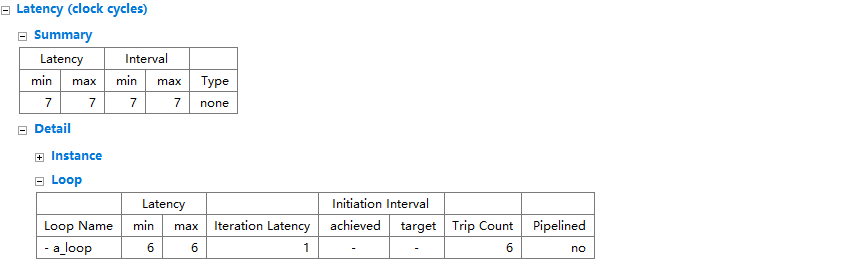 可以看到,循环以后的综合报告变成了一个循环,Trip Count取最大的,同时整体的Latency和资源占用降低了。
对于循环是变量的,可以根据循环边界的大小,改写源码拆分循环,达到loop merge的条件。
循环合并的时候两个循环体里面不要有数据依赖。
DATAFLOW:
下面这段代码,各个循环之间有数据依赖,每个循环之间的数据传输可以称之为channel,这些channel可以用ping-pong ram, fifo或者register
可以看到,循环以后的综合报告变成了一个循环,Trip Count取最大的,同时整体的Latency和资源占用降低了。
对于循环是变量的,可以根据循环边界的大小,改写源码拆分循环,达到loop merge的条件。
循环合并的时候两个循环体里面不要有数据依赖。
DATAFLOW:
下面这段代码,各个循环之间有数据依赖,每个循环之间的数据传输可以称之为channel,这些channel可以用ping-pong ram, fifo或者register


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1...
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用